Datasets
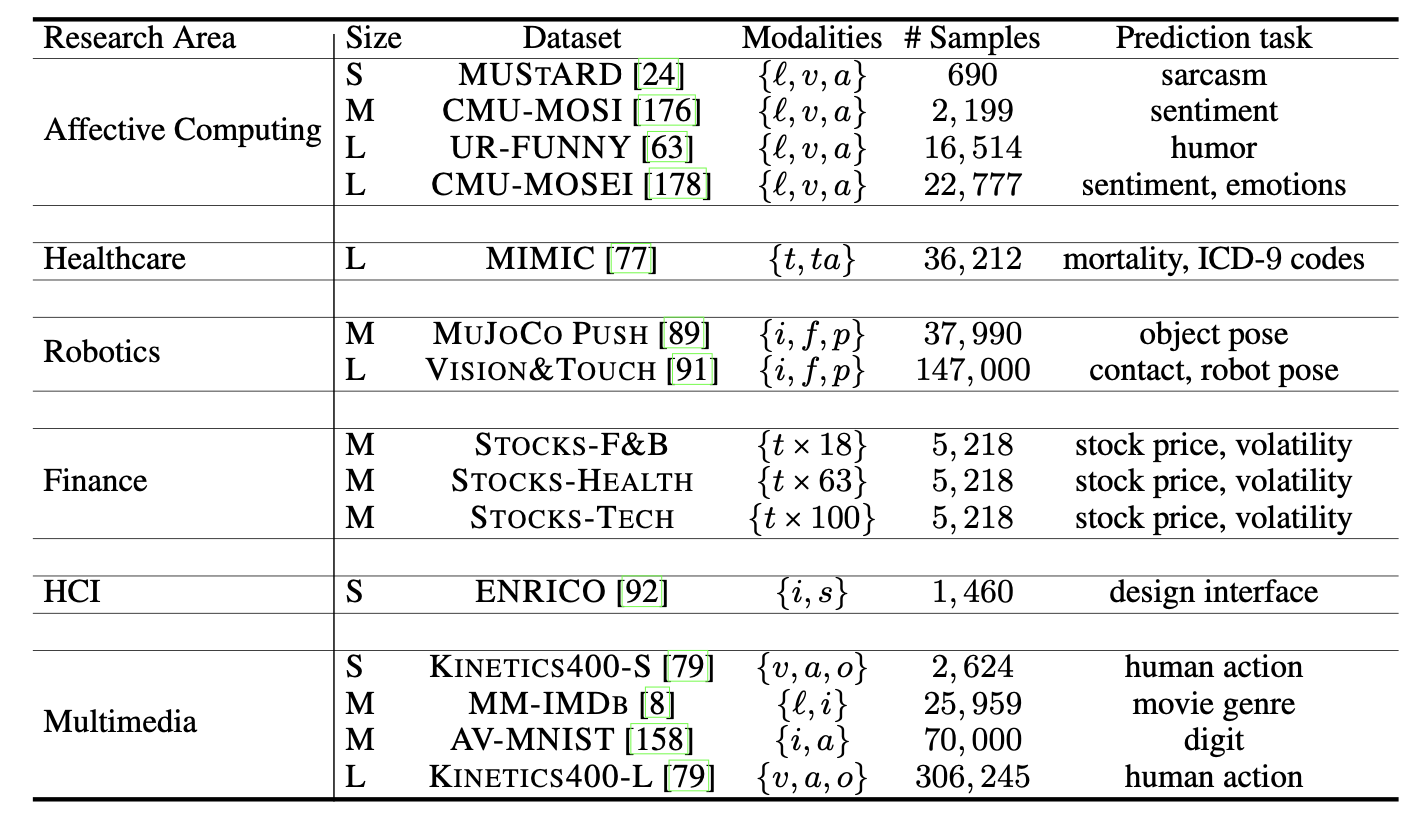
Affective Computing:
- MUStARD is a multimodal video corpus for research in automated sarcasm discovery compiled from popular TV shows including Friends, The Golden Girls, The Big Bang Theory, and Sarcasmaholics Anonymous. MUStARD consists of audiovisual utterances annotated with sarcasm labels. Each utterance is accompanied by its context, which provides additional information on the scenario where the utterance occurs, thereby providing a further challenge in the long-range modeling of multimodal information.
- CMU-MOSI is a collection of 2,199 opinion video clips each rigorously annotated with labels for subjectivity, sentiment intensity, per-frame, and per-opinion annotated visual features, and per-milliseconds annotated audio features. Each video is collected from YouTube with a focus on video blogs, or vlogs which reflect the real-world distribution of speakers expressing their behaviors through monologue videos.
- UR-FUNNY is the first large-scale multimodal dataset of humor detection in human speech involving the effective use of words (text), accompanying gestures (visual), and prosodic cues (acoustic). UR-FUNNY consists of more than 16,000 video samples from TED talks which are among the most diverse idea-sharing channels covering speakers from various backgrounds, ethnic groups, and cultures discussing a variety of topics from discoveries in science and arts to motivational speeches and everyday events.
- CMU-MOSEI is the largest dataset of sentence-level sentiment analysis and emotion recognition in real-world online videos with more than 65 hours of annotated video from more than 1,000 speakers and 250 topics. Each video is annotated for sentiment as well as the presence of 9 discrete emotions (angry, excited, fear, sad, surprised, frustrated, happy, disappointed, and neutral) as well as continuous emotions (valence, arousal, and dominance).
Healthcare:
- MIMIC is a large, freely-available database comprising de-identified health-related data associated with over 40,000 patients who stayed in critical care units of the Beth Israel Deaconess Medical Center between 2001 and 2012. We organized numerous patient data into two major modalities: time series modality, which is a set of medical measurements of the patient taken every hour in a period of 24 hours where each measurement and static modality, which is a set of medical information about the patient. We use these modalities for $3$ tasks: mortality prediction and 2 ICD-9 code predictions.
Robotics:
- MuJoCo Push is a planar pushing task, in which a 7-DoF Panda Franka robot is pushing a circular puck with its end-effector in simulation. We estimate the 2D position of the unknown object on a table surface, while the robot intermittently interacts with the object. Similar to Vision&Touch, planar pushing is a contact-rich task. However, instead of estimating robot states, this dataset is estimating the state of the object the robot is currently interacting with.
- Vision & Touch is a real-world robot manipulation dataset that collects visual, force, and robot proprioception data (as well as the robot actions) for a peg insertion task. The robot is a 7-DoF, torque-controlled Franka Panda robot, which has a triangle peg attached to its end-effector. Rigidly attached to the table in front of the robot is a box with a triangle hole. The robot attempts to insert the peg into the hole, a contact-rich manipulation task that has been studied for decades due to its relevance in manufacturing. Vision, force, and proprioception are feedback modalities shown to be complementary and concurrent during contact-rich manipulation.
Finance:
- Stocks-F&B consists of 8 selected stocks from S&P 500 stocks categorized by GICS as Restaurants or Packaged Foods & Meats. We select MCD, SBUX, HSY, and HRL for initial experiments on this dataset, record their opening prices and preprocess the data.
- Stocks-Health consists of 63 selected stocks from S&P $500$ stocks categorized by GICS as Health Care. We select MRK, WST, CVS, MCK, ABT, UNH, and TFX for initial experiments on this dataset, record their opening prices, and preprocess the data.
- Stocks-Tech consists of 100 selected stocks from S&P 500 stocks categorized by GICS as Information Technology or Communication Services. We select AAPL, MSFT, AMZN, INTC, AMD, and MSI for initial experiments on this dataset, record their opening prices, and preprocess the data.
HCI:
- ENRICO is a dataset of Android app screens categorized by their design motifs. ENRICO was collected to help data-driven design applications such as design search, UI layout generation, UI code generation, and user interaction modeling. ENRICO is a subset of RICO, which is a large dataset of app screens collected by the automated and semi-automated crawling of Android apps available on the Google Play Store.
Multimedia:
- MM-IMDb is the largest publicly available multimodal dataset for genre prediction on movies starting from the movies of the MovieLens 20M dataset and expanded by collecting genre, poster, and plot information for each movie. The final dataset contains ratings for 25,959 movies.
- AV-MNIST is a multimodal dataset created by paring audio of a human reading digits from the FSDD dataset with written digits in the MNIST dataset with tasked to predict the digit into one of 10 classes (0-9).
- Kinetics-400 is a series of large-scale curated video clips covering a diverse range of 400 human action classes, with at least 400 video clips for each action. Each clip lasts around 10s and is taken from a different YouTube video. This is one of the largest publicly available multimodal datasets with a total of 306,245 video clips spanning 400 human actions.