MultiBench
Multiscale Benchmarks for Multimodal Representation Learning
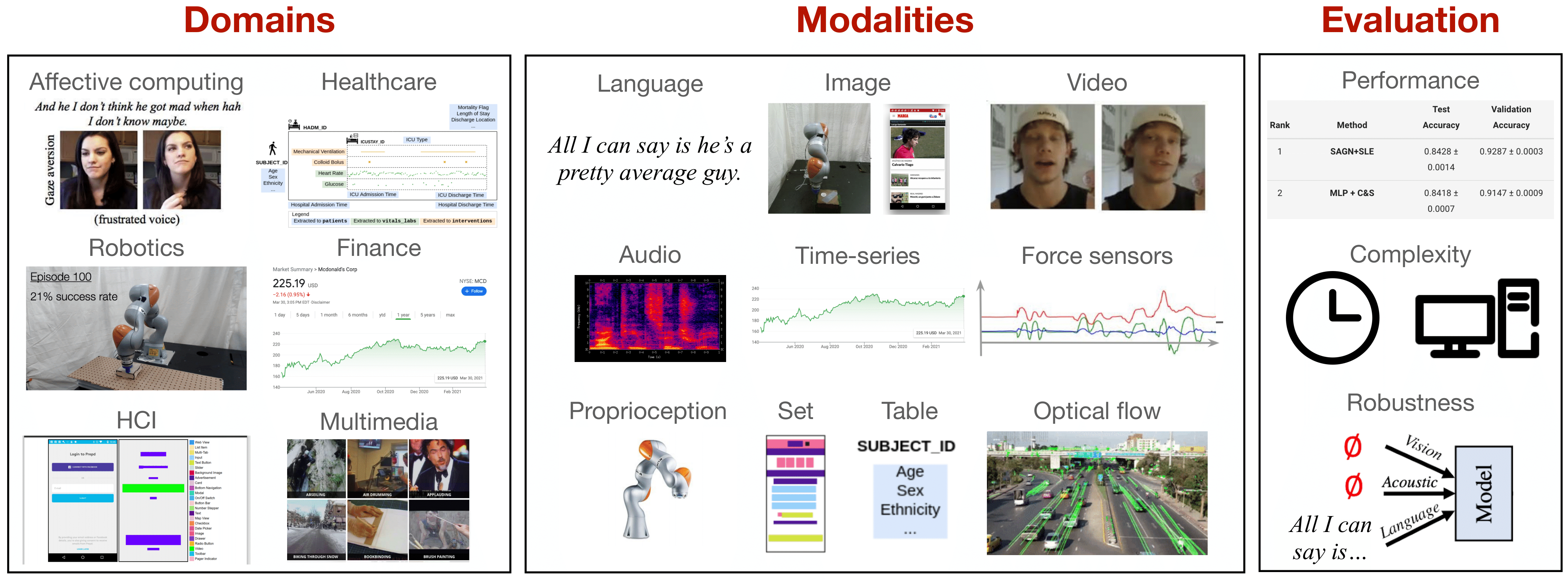
Learning multimodal representations involves integrating information from multiple heterogeneous sources of data. It is a challenging yet crucial area with numerous real-world applications in multimedia, affective computing, robotics, finance, human-computer interaction, and healthcare. Unfortunately, multimodal research has seen limited resources to study (1) generalization across domains and modalities, (2) complexity during training and inference, and (3) robustness to noisy and missing modalities.
In order to accelerate progress towards understudied modalities and tasks while ensuring real-world robustness, we release MultiBench, a systematic and unified large-scale benchmark for multimodal learning spanning 15 datasets, 10 modalities, 20 prediction tasks, and 6 research areas. MultiBench provides an automated end-to-end machine learning pipeline that simplifies and standardizes data loading, experimental setup, and model evaluation. To enable holistic evaluation, MultiBench offers evaluation methodology to study (1) generalization, (2) time and space complexity, and (3) modality robustness.
To accompany MultiBench, we also provide a standardized implementation of 20 core approaches in multimodal learning unifying innovations in fusion paradigms, optimization objectives, and training approaches which we call MultiZoo.
We hope that MultiBench will present a milestone in unifying disjoint efforts in multimodal machine learning research, paving the way towards a better understanding of the capabilities and limitations of multimodal models, all the while ensuring ease of use, accessibility, and reproducibility. MultiBench, MultiZoo, and leaderboards are publicly available, will be regularly updated, and welcomes inputs from the community.
- MultiBench data and MultiZoo code: https://github.com/pliang279/MultiBench

- Paul Liang, CMU MLD
- Email: pliang@cs.cmu.edu

- Yiwei Lyu, CMU MLD
- Email: ylyu1@cs.cmu.edu

- Xiang Fan, CMU CSD
- Email: xiangfan@cmu.edu

- Zetian Wu, Johns Hopkins
- Email: zwu49@jhu.edu


- Jason Wu, CMU HCI
- Email: jsonwu@cmu.edu

- Leslie Chen, Northeastern University
- Email: lesliechen1998@gmail.com

- Peter Wu, CMU MLD
- Email: peterw1@cs.cmu.edu


- Yuke Zhu, UT Austin
- Email: yukez@cs.utexas.edu


Announcements
| June 1, 2021 | Welcome to MultiBench! Please check out data and code here: https://github.com/pliang279/MultiBench. We will be releasing a technical report describing MultiBench and enabling submissions soon! |